

All software systems have a capacity that determines how much work they can process at any given time. This could mean maximum CPU, memory or network bandwidth load.
There are two ways to scale a system:
increase resources of a single unit in a system (aka vertical scaling)
introduce more units to the system and coordinate their work (aka horizontal scaling)
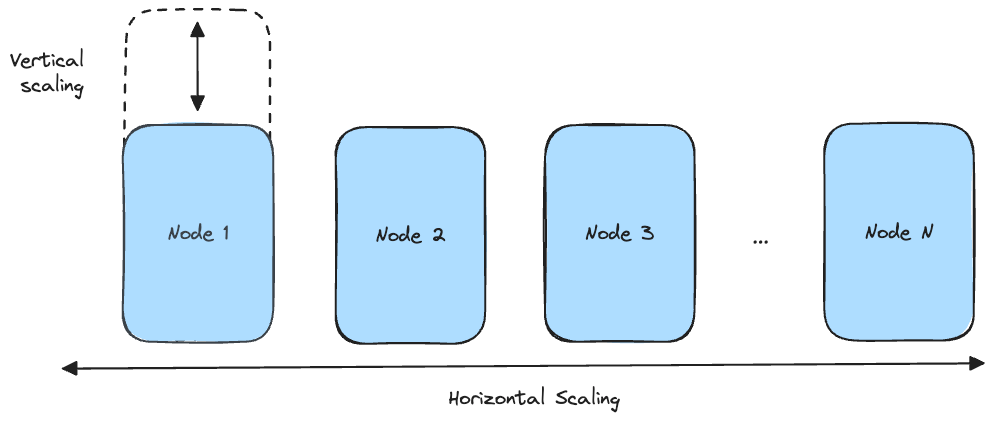
Vertical scaling is limited. There is only so much better hardware we can add to a single machine and the cost to improvement ratio is not favourable.
Horizontal scaling is much more attainable. As long as we can coordinate the work effectively, we can scale infinitely. This is how most distributed systems are scaled.
However, the caveat is “coordinate the work effectively”. Thus, how do we manage work between multiple workers in a distributed system?
Adding more processing units to a system will increase the system’s compute capacity. However, there is still a natural limit. A system can only process so many tasks at a time.
To avoid overwhelming the system we can introduce queues that put tasks in temporary storage for future processing and enables us to throttle the load on the system.
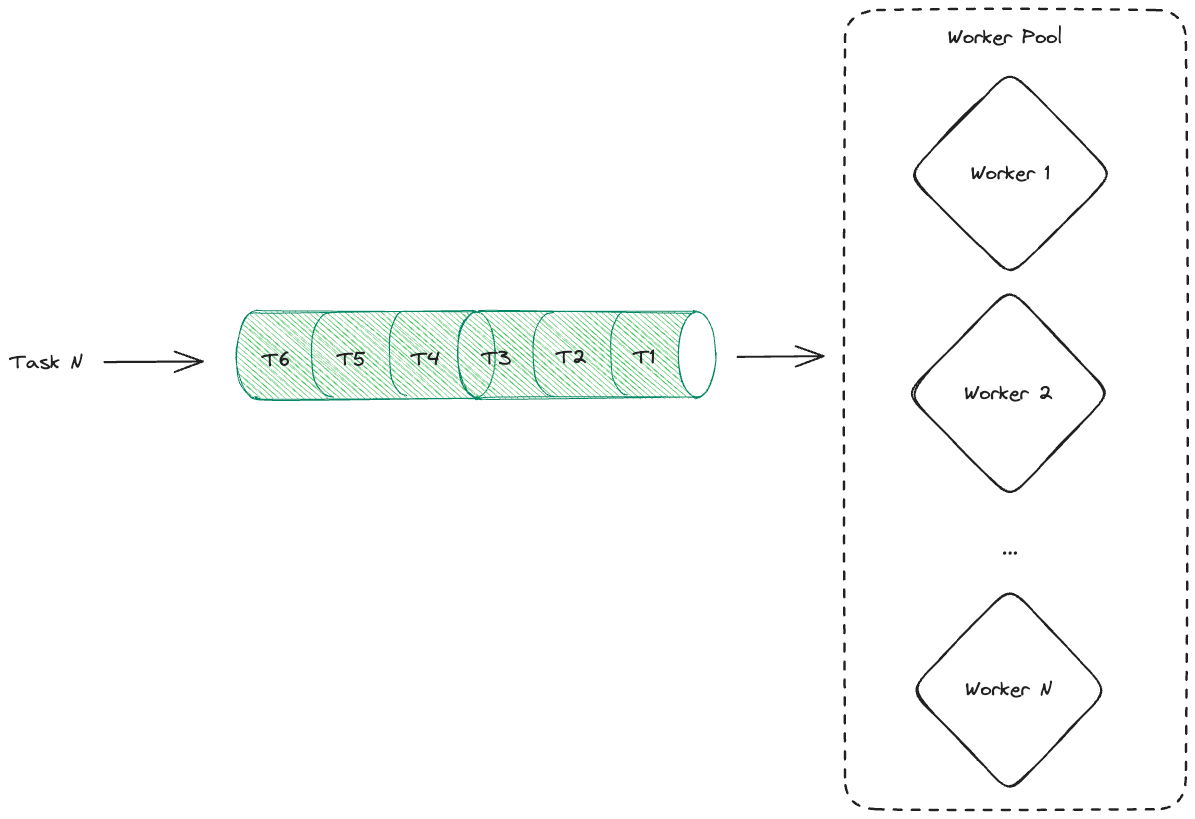
These queues are accessed by workers. They consume one task at a time from a queue, process it and repeat until there are no more tasks in the queue. A worker here can be any part of the distributed system that performs some kind of processing.
There are two parameters we can tweak here: queue size and the number of workers in the pool.
Increasing the number of workers allows us to process more work and reduce the backlog of work that has accumulated in the queues faster.
Having more queue space allows us to accumulate more work for processing while maintaining a constant load on the workers' pool and not discarding any incoming requests.
The downside of this approach is that it can only be used for asynchronous requests.
For example, imagine a user uploading a photo and posting it to a chat-based application. Once the photo is uploaded, it can be compressed asynchronously for more efficient storage. In contrast, if a user types a character as part of the search query, we would expect the suggested results to appear instantly which would most likely be achieved with a synchronous request-response1.
Most user requests need to be handled synchronously to ensure low latency. However, internally, for processing that is not required to immediately satisfy the user, queues and workers are the way to coordinate and distribute non-trivial work.
In particular, system components might not receive the same load to process requests. One service might create a notification that needs to be sent to millions of users and forward it to a notifications service. Each user message would need to be sent separately putting a significant load on the dispatch component. Instead of doing all the work at once, the service could split the work into chunks, put them into a queue and tackle at a comfortable pace.
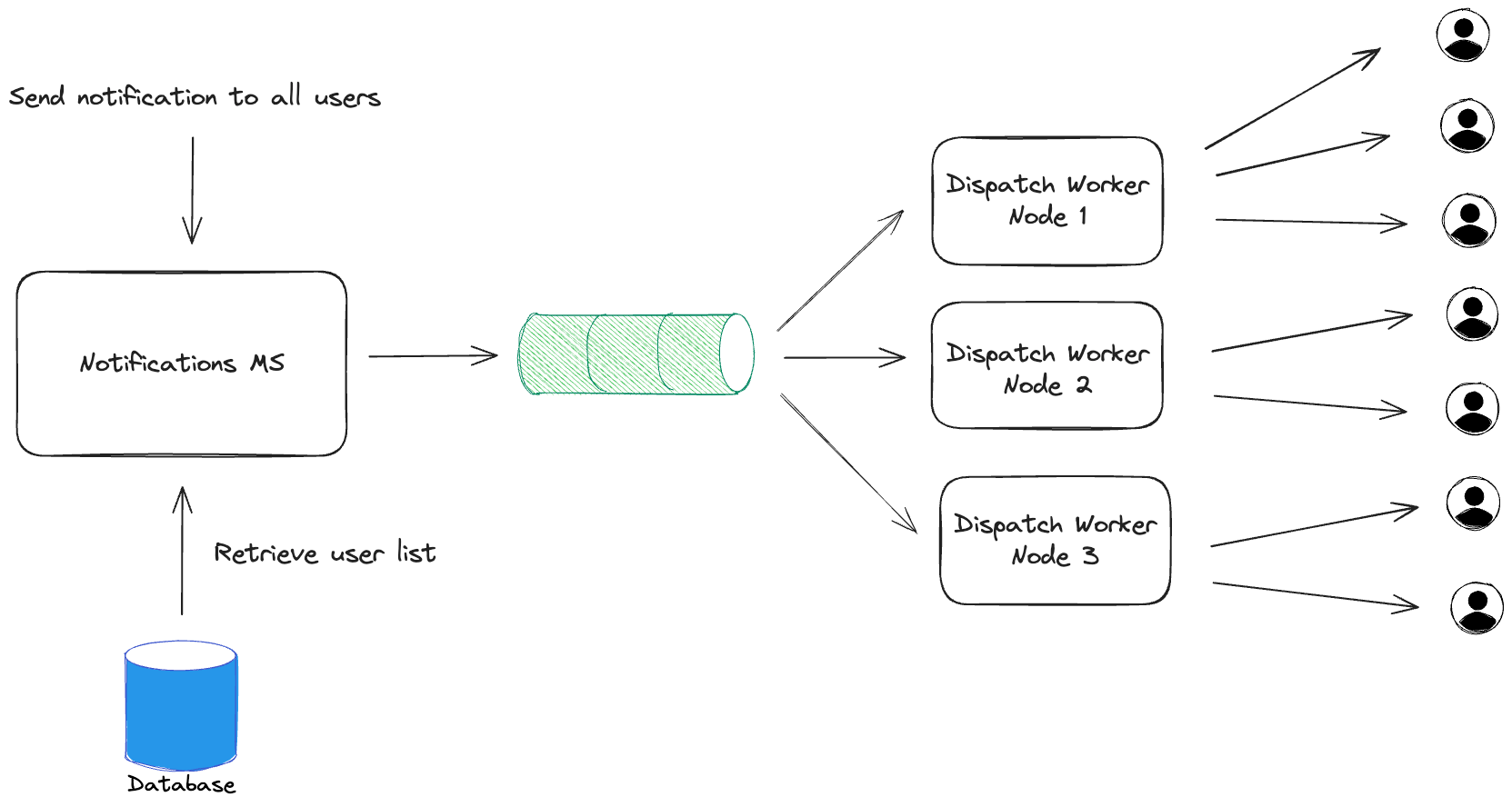
Worker Queue Pattern
The worker queue pattern allows to build systems in a way where the load of any single component of the system can be throttled and controlled to avoid overwhelming it and taking the whole system down.
In more abstract terms, it allows to decouple request submissions from processing. Not all requests require immediate response. However, all requests require an acknowledgment of receipt. This separation of concerns is what enables a system to scale.
The same underlying principles are present in other, more context-specific patterns:
Summary
Distributed systems contain components with varied resources and processing capabilities. To scale systems, we need a mechanism to control the load on any given component in the system. For work that can be done asynchronously, we can use workers and queues. Queues provide a way to buffer work, while workers process the work at a predictable and comfortable pace. This makes the system easy to scale - add more queues and workers to handle a higher load.
Instantly is an ambiguous term and it might not require a synchronous response. One could imagine a queue-worker-based system that processes requests so quickly that it appears to the user as if there was a synchronous request-response without any delay.
https://en.wikipedia.org/wiki/Producer%E2%80%93consumer_problem
https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern
https://en.wikipedia.org/wiki/Event-driven_architecture